puppeteer 前端自动化测试实践

puppeteer 简介
puppeteer 中文翻译为”操纵木偶的人”,谷歌浏览器在 17 年自行开发了 Chrome Headless 特性,并与之同时推出了 puppeteer, 可以理解为我们日常使用的 Chrome 的无界面版本以及对其进行操控的 js 接口套装。
使用 puppeteer 实际上是通过调用 Chrome DevTools Protocol 开放的接口与 Chrome 通信。 Chrome DevTools Protocol 的接口很复杂, puppeteer 为此封装了一些调用方便的接口供使用。
puppeteer 要求使用 Node v6.4.0,但实际代码中大量使用 async/await,需要 Node v7.6.0 及以上
Chrome DevTool Protocol
- 基于 websocket 实现与浏览器内核的快速数据通道
- 协议中分为多个域如:DOM、Debugger、NetWork、Profiler、Console 等等。每个域中都定义了相关的命令和事件
- 业界内的 Chrome 开发者工具、puppeteer 都是基于 Chrome DevTool Protocol 实现的
Headless Chrome
- 在无界面的环境中运行 Chrome
- 通过命令行或者程序语言操作 Chrome
操作系统 win10:
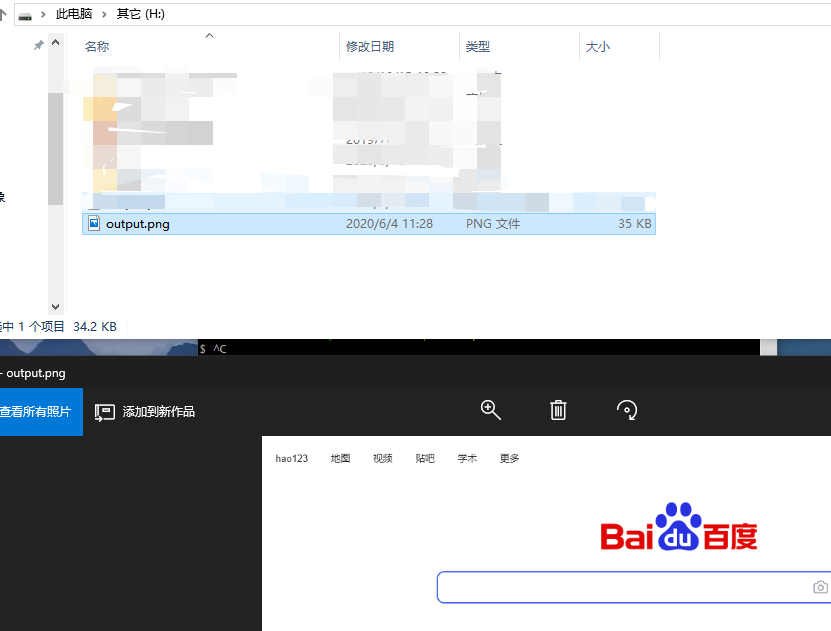
访问页面并截图
"C:\Users\baoshi\AppData\Local\Google\Chrome\Application\chrome" --headless --disable-gpu --screenshot=H:\output.png https://www.baidu.com
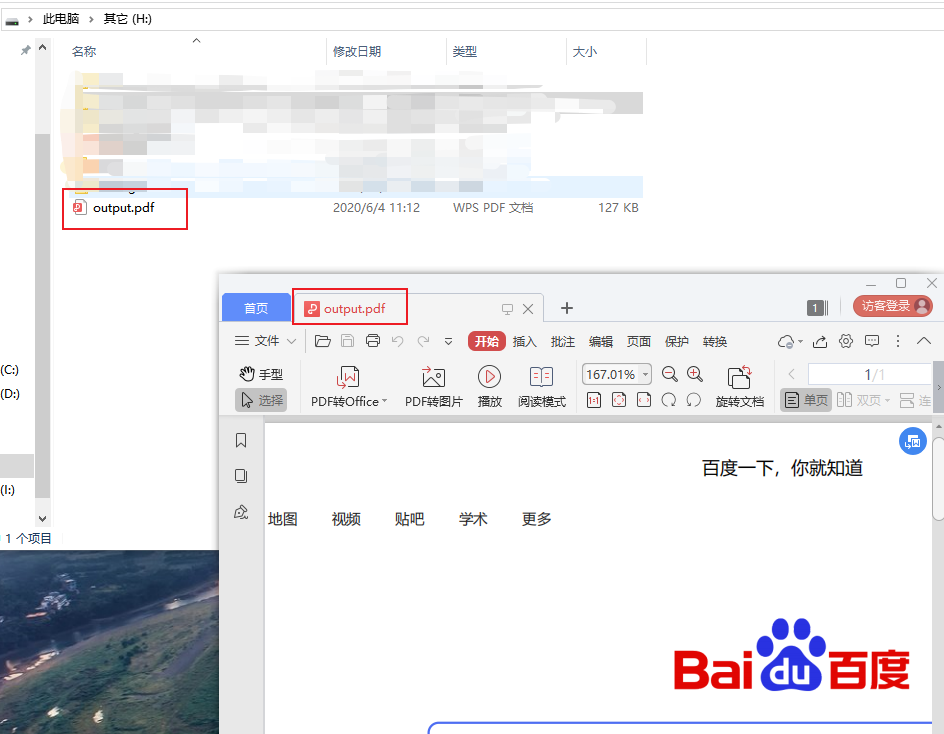
访问页面并将页面输出为 pdf 文件
"C:\Users\baoshi\AppData\Local\Google\Chrome\Application\chrome" --headless --disable-gpu --print-to-pdf=H:\output.pdf https://www.baidu.com
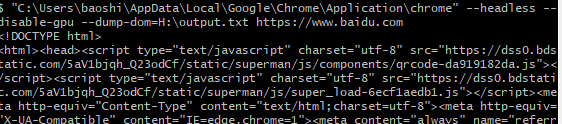
访问页面并下载页面 dom
"C:\Users\baoshi\AppData\Local\Google\Chrome\Application\chrome" --headless --disable-gpu --dump-dom https://www.baidu.com
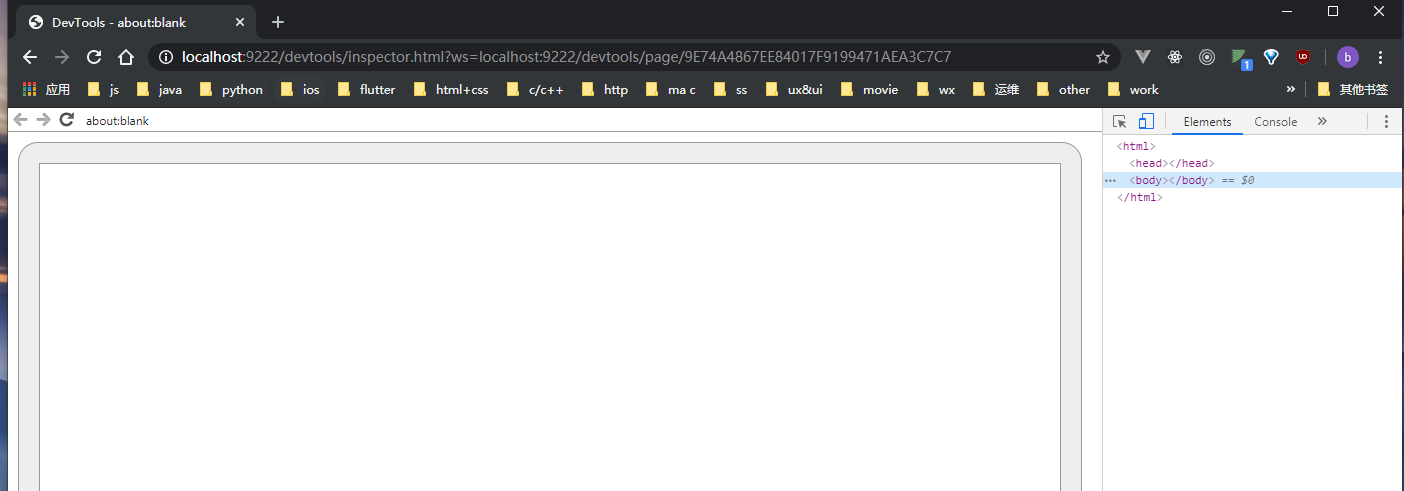
开启远程调试
"C:\Users\baoshi\AppData\Local\Google\Chrome\Application\chrome" --headless --remote-debugging-port=9222 --disable-gpu

Chrome 与 Chromium 区别


Chromium 是谷歌为了研发 Chrome 而启动的项目,两者基于相同的源代码构建,Chrome 所有的新功能都会先在 Chromium 上实现,待验证稳定后才会移植,因此 Chromium 的版本更新频率更高,也会包含很多新的功能。
- Chromium 采用的 BSD 开源协议
- Chrome 是闭源的
- Chromium 不会搜集用户信息
- Chrome 和 Chromium 都能通过“扩展程序”增强浏览器的功能,Chrome 默认从网上应用店里安装扩展程序,而 Chromium 无法访问网上应用店,只能添加外部扩展程序
- Chromium 没有 Flash 和编解码器的支持,如:AROM,AAC,MP3,H.264
puppeteer 能做什么
- puppeteer 通过封装了 Chrome DevTools Protocol 的接口,从而控制 Chromium/Chrome 浏览器的行为
- puppeteer 默认以 headless 模式启动 Chrome,可以通过设计参数启动有界面的 Chrome
- 网页截图或者生成 PDF
- 爬取 SPA 或 SSR 网站
- UI 自动化测试,模拟表单提交,键盘输入,点击等行为
- 捕获网站的时间线,帮助诊断性能问题
- 创建一个最新的自动化测试环境,使用 js 和 Chrome 浏览器运行测试用例
- ……
puppeteer API 分层结构
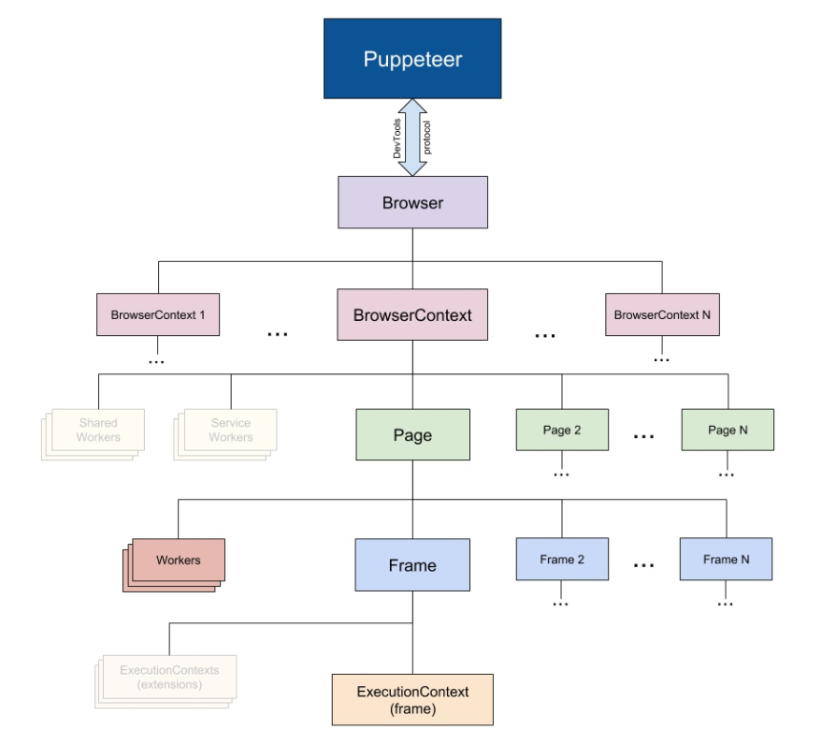
puppeteer 涉及的主要概念如下:
- Browser 对应一个浏览器实例, 一个 Browser 可以包含多个 BrowserContext
- BrowserContext 对应一个浏览器的上下文会话,当浏览器启动时,它已经默认使用一个 BrowserContext, 通过使用
browser.createIncognitoBrowserContext()方法创建隐藏的浏览器上下文。其中 BrowserContext 之间 Session 、Cookie 等都是相互独立的互不影响。 一个 BrowserContext 包含多个 Page。 - Page 表示一个 Tab 页面, 可以通过
browserContext.newPage()/browser.newPage()创建, 区别在于browser.newPage()会调用默认的browserContext创建。一个 Page 包含多个 Frame - Frame 一个框架 可以理解为 html 中的 iframe 标签
- ExecutionContext 是 javascript 的执行环境
- ElementHandle 对应 DOM 的一个元素节点, 通过该实例可以实现对元素的点击及填写表单等行为。可以通过选择器或 xpath 获取对应的元素
- JSHandle 表示一个页面内 JavaScript 对象。 JSHandles 可以使用 page.evaluateHandle 方法创建。, ElementHandle 继承自 JsHandle
- CDPSession 可以直接与原生的 Chrome DevTools Protocol 通信,通过
session.send调用及session.on方法订阅 - Coverage 收集相关页面使用的 javascript 及 css 信息
- Tracing 抓取性能数据进行分析, 通过使用
tracing.start和trace.stop创建一个可以在 Chrome DevTools 或者 timeline viewer 中打开的跟踪文件 - Request 页面收到的请求 可以基于
page.on('request',() => {})监听页面的请求 - Response 页面发出的响应 可以基于
page.on('reponse',() => {})监听页面的返回结果
创建 Browser 实例
- puppeteer.connect 连接一个已经存在的 chrome 实例
- puppeteer.launch 每次都启动一个 Chrome 实例
launch
const puppeteer = require('puppeteer')
;(async () => {
const browser = await puppeteer.launch({
headless: false,
slowMo: 100,
defaultViewport: { width: 1440, height: 1000 },
args: [`--window-size=${1440},${1000}`],
ignoreHTTPSErrors: false, //忽略 https 报错
})
const page = await browser.newPage()
await page.goto('https://www.baidu.com')
})()
connect
const puppeteer = require('puppeteer')
let browserWSEndpoint = ''
;(async () => {
const options = {
headless: false,
slowMo: 100,
defaultViewport: { width: 1440, height: 1000 },
args: [`--window-size=${1440},${1000}`],
ignoreHTTPSErrors: false, //忽略 https 报错
}
const browser = await puppeteer.launch({
...options,
})
browserWSEndpoint = browser.wsEndpoint()
// 从Chromium断开和puppeteer的连接
browser.disconnect()
//直接连接已经存在的 Chrome
const browser2 = await puppeteer.connect({
...options,
browserWSEndpoint,
})
const page = await browser2.newPage()
await page.goto('https://www.baidu.com')
})()
如何等待加载
往往我们使用 puppeteer 在页面执行或加载的某一时机截图或者获取页面信息。以下将等带加载的 api 分为以下三类:
加载导航页面
- page.goto 打开新页面
- page.goBack 回退到上一个页面
- page.goForward 前进到下一个页面
- page.reload 重新加载页面
- page.waitForNavigation 等待页面跳转
这些 api 都可以通过使用 waitUntil 配置达到满足条件认为页面跳转完成。默认 load 事件触发时,页面加载完成。
- load 页面的 load 事件触发
- domcontentloaded 页面的 DOMContentLoaded 事件触发
- networkidle0 不再有网络连接时触发
- networkidle2 只有两个网络连接时触发
const puppeteer = require('puppeteer')
;(async () => {
const browser = await puppeteer.launch({
slowMo: 100,
headless: false,
defaultViewport: { width: 1440, height: 1000 },
args: [`--window-size=${1440},${1000}`],
ignoreHTTPSErrors: false, //忽略 https 报错
})
const page = await browser.newPage()
await page.goto('http://www.baidu.com', {
// timeout 表示如果超过这个时间还没有结束就抛出异常
timeout: 30 * 1000,
waitUtil: ['networkidle0'],
})
console.log('page load finished!')
})()
等待元素、请求、响应
- page.waitForXPath 等待 XPath 对应的元素出现, 返回对应的 ElementHandle 实例
- page.waitForSelector 等待选择器对应的元素出现,返回对应的 ElementHandle 实例
const puppeteer = require('puppeteer')
;(async () => {
const browser = await puppeteer.launch({
slowMo: 100,
headless: false,
defaultViewport: { width: 1440, height: 1000 },
args: [`--window-size=${1440},${1000}`],
ignoreHTTPSErrors: false, //忽略 https 报错
})
const page = await browser.newPage()
page.goto('http://www.baidu.com')
await page.waitForRequest(
'https://www.baidu.com/img/flexible/logo/pc/result.png'
)
console.log('request loaded')
await page.waitForResponse(
'https://www.baidu.com/img/flexible/logo/pc/result.png'
)
console.log('respone loaded')
await page.waitForXPath('//img')
console.log('image loaded')
await page.waitForSelector('[href="http://xueshu.baidu.com"]')
console.log('selector loaded')
})()
自定义等待
- page.waitForFunction 等待页面中自定义函数的执行结果,返回 JsHandle 实例, 其中第一个参数要在浏览器实例上下文执行的方法
- page.waitFor 设置等待时间
const puppeteer = require('puppeteer')
;(async () => {
const browser = await puppeteer.launch({
slowMo: 100,
headless: false,
defaultViewport: { width: 1440, height: 1000 },
args: [`--window-size=${1440},${1000}`],
ignoreHTTPSErrors: false, //忽略 https 报错
})
const page = await browser.newPage()
await page.goto('http://www.baidu.com')
await page.waitFor(5000)
console.log('waitFor finished')
await page.setViewport({
width: 50,
height: 50,
})
await page.waitForFunction('window.innerWidth < 100')
console.log('waitForFunction finished')
})()
截图
屏幕截图
const puppeteer = require('puppeteer')
;(async () => {
const browser = await puppeteer.launch()
const page = await browser.newPage()
await page.goto('https://www.baidu.com')
// 页面截图
await page.screenshot({
path: './files/capture.png',
type: 'png',
fullPage: true,
})
console.log('page captured!')
})()
Dom 元素截图
const puppeteer = require('puppeteer')
;(async () => {
const browser = await puppeteer.launch()
const page = await browser.newPage()
await page.goto('https://www.baidu.com')
// 页面元素截图
const element = await page.$('#su')
await element.screenshot({
path: './files/button.png',
type: 'png',
})
console.log('button captured!')
})()
page.$('.classname')获取某个选择器对应的第一个元素 querySelectorpage.$$('.classname')获取某个选择器对应所有元素 querySelectorAllpage.$x('//img')获取某个 xPath 对应的所有元素page.waitForXPath('//img')等待某个 xPath 对应的元素出现page.waitForSelector('.classname')等待某个选择器对应的元素出现
模拟用户登录
const puppeteer = require('puppeteer')
;(async () => {
const browser = await puppeteer.launch({
headless: false,
})
const page = await browser.newPage()
await page.goto('http://10.9.9.76:8801/iomp', {
waitUntil: 'networkidle0',
})
const username = await page.$('[placeholder="请输入用户名"]')
const password = await page.$('[placeholder="请输入用户密码"]')
const button = await page.$('.el-button--primary')
await username.type('admin', { delay: 50 })
await password.type('kedacom', { delay: 50 })
// 待页面跳转完成,一般点击某个按钮需要跳转时,都需要等待 page.waitForNavigation() 执行完毕才表示跳转成功
await Promise.all([button.click(), page.waitForNavigation()])
await page.screenshot({
path: './files/home.png',
type: 'png',
})
console.log()
page.close()
browser.close()
})()
ElementHandle 提供了一下操作元素的方法
- elementHandle.click() 点击某个元素
- elementHandle.tap() 模拟手指触摸点击
- elementHandle.focus() 聚焦点击某个元素
- elementHandle.hover() 鼠标 hover 到某个元素上
- elemntHandle.type(‘hello’) 在输入框输入文本
请求拦截
请求的拦截需要提前开启 page.setRequestInterception(true)
监听的请求的类型有: document,stylesheet,image,media,font,script,texttrack,xhr,fetch,eventsource,websocket,manifest,other
const puppeteer = require('puppeteer')
;(async () => {
const browser = await puppeteer.launch({
headless: false,
defaultViewport: { width: 1440, height: 1000 },
args: [`--window-size=${1440},${1000}`],
ignoreHTTPSErrors: false, //忽略 https 报错
})
const page = await browser.newPage()
const blockTypes = ['image']
// 开启拦截请求
await page.setRequestInterception(true)
page.on('request', (request) => {
const type = request.resourceType()
const shouldBlock = blockTypes.includes(type)
if (shouldBlock) {
return request.abort()
} else {
// 重写请求
return request.continue({
headers: Object.assign({}, request.headers, {
'puppeteer-test': 'true',
}),
})
}
})
await page.goto('https://www.baidu.com')
})()
page 对象除了监听 request, 也可以监听一下事件:
page.on('close')页面关闭page.on('console')console API 被调用page.on('error')页面出错page.on('load')页面加载完成page.on('request')收到请求page.on('requestfailed')请求失败page.on('requestfinished')页面中某个请求成功page.on('response')收到响应
获取 WebSocket 响应
puppeteer 目前没有提供原生的用于处理 WebSocket 的 API 接口, 但是我们可以通过更底层的 Chrome DevTool Protocol(CDP) 实现, 也就是上面提到的 CDPSession。
const puppeteer = require('puppeteer')
;(async () => {
const browser = await puppeteer.launch({
headless: false,
})
const page = await browser.newPage()
// 创建 cdp 会话
let cdpSession = await page.target().createCDPSession()
// 开启网络调试,监听 Chrome DevTools Protocol 中 Network 事件
await cdpSession.send('Network.enable')
// 监听 websocket received 事件
cdpSession.on('Network.webSocketFrameReceived', (frame) => {
let payloadData = frame.response.payloadData
console.log('websocket payloadData:', payloadData)
})
// 进入页面触发 websocket 按钮
await page.goto('http://10.9.9.76:8801/iomp/#/login', {
waitUntil: 'networkidle0',
})
const username = await page.$('[placeholder="请输入用户名"]')
const password = await page.$('[placeholder="请输入用户密码"]')
const button = await page.$('.el-button--primary')
await username.type('admin', { delay: 50 })
await password.type('kedacom', { delay: 50 })
await Promise.all([button.click(), page.waitForNavigation()])
await page.goto('http://10.9.9.76:8801/iomp/#/service/list')
await page.waitFor(4000)
const terminal = await page.$('.icon-zhongduan')
await terminal.click()
})()
植入 javascript 代码
puppeteer 最强大的功能是,可以在浏览器中执行任何想到运行的 javascript 代码。
const puppeteer = require('puppeteer')
;(async () => {
const browser = await puppeteer.launch({
headless: false,
defaultViewport: { width: 1440, height: 1000 },
args: [`--window-size=${1440},${1000}`],
ignoreHTTPSErrors: false, //忽略 https 报错
})
const page = await browser.newPage()
await page.goto('https://www.baidu.com', {
waitUntil: 'networkidle0',
})
await page.evaluate(async () => {
const element = document.querySelector('#su')
element.style.color = 'red'
})
})()
除了 evaluate 方法外, page 还提供以下方法:
1.page.evaluateHandle 与 page.evaluate 的区别在于, page.evaluateHandle 执行完成后返回 JSHandle 对象,此 JSHandle 对象 ,可作为 page.evaluateHandle 的参数,传递给内部的 pageFunction 使用
const aHandle = await page.evaluateHandle('document') // 'document'对象
const aHandle = await page.evaluateHandle(() => document.body)
const resultHandle = await page.evaluateHandle(
(body) => body.innerHTML,
aHandle
)
console.log(await resultHandle.jsonValue())
await resultHandle.dispose()
2.page.$$eval 把 selector 对应的所有元素传入到第二个函数参数中,供在浏览器环境中执行
const divsCounts = await page.$$eval('div', (divs) => divs.length)
3.page.$eval 把 selector 匹配的第一个元素传入到第二个函数参数中,供在浏览器环境中执行
const searchValue = await page.$eval('#search', (el) => el.value)
const preloadHref = await page.$eval('link[rel=preload]', (el) => el.href)
const html = await page.$eval('.main-container', (e) => e.outerHTML)
4.page.evaluateOnNewDocument指定的函数在所属的页面被创建并且所属页面的任意 script 执行。1. 页面导航完成后 2. 页面的 iframe 加载或导航完成
5.page.exposeFunction 添加一个挂载到浏览器 window 的方法, 当执行新添加的方法后, 实际上是调用 nodejs 中的方法
const puppeteer = require('puppeteer')
const crypto = require('crypto')
puppeteer.launch().then(async (browser) => {
const page = await browser.newPage()
page.on('console', (msg) => console.log(msg.text()))
await page.exposeFunction('md5', (text) =>
crypto.createHash('md5').update(text).digest('hex')
)
await page.evaluate(async () => {
// use window.md5 to compute hashes
const myString = 'PUPPETEER'
const myHash = await window.md5(myString)
console.log(`md5 of ${myString} is ${myHash}`)
})
await browser.close()
})
puppeteer 团队内应用场景
巡检任务
系统内某些关键的操作流程,我们可以通过 puppeteer 定时访问并执行操作,并将执行结果报告定时邮件发送。
以海豚发布项目为例,发布流程为此系统的关键流程,巡检代码如下:
phantomjs vs puppeteer
phantomjs 是 一个基于 webkit 内核(较老版本)的无头浏览器,没有 UI 界面。
虽然 phantomjs 是 fully functional headless browser,但是它和真正的浏览器还是有很大的差别,并不能完全模拟真实的用户操作。Headless Chrome 是 Chrome 浏览器的无界面形态,可以在不打开浏览器的前提下使用所有 Chrome 支持的特性。
更加便利的调试,我们只需要在命令行中加入–remote-debugging-port=9222,再打开浏览器输入 localhost:9222(ip 为实际运行命令的 ip 地址)就能进入调试界面。
puppeteer 比 phantomjs 拥有更好的性能,下图为 Chrome 60.0.3112.113 和 phantomjs 2.1.1 ,相同的页面加载 1000 对比结果。
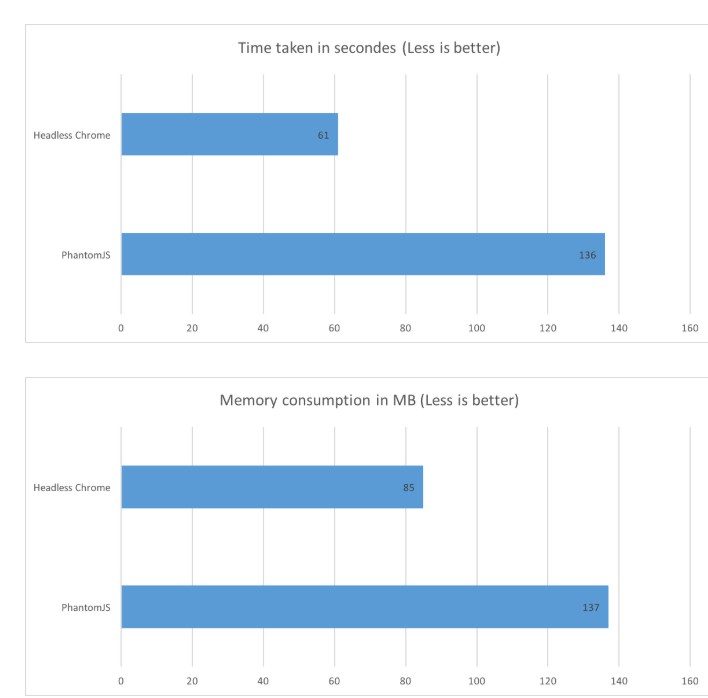
随着 phantomjs 使用,phantomjs bug 越来越多,同时此项目目前无人维护了。
selenium vs puppeteer
selenium 与 puppeteer 都是基于 Chrome DevTools Protocol 来操控 Chrome 的。了解 selenium 需要提前了解一下 webdriver。
selenium 2,又名 WebDriver,它的主要新功能是集成了 selenium 1.0 以及 WebDriver(WebDriver 曾经是 selenium 的竞争对手)。也就是说 selenium 2 是 selenium 和 webDriver 两个项目的合并,即 selenium 2 兼容 Selenium,它既支持 selenium API 也支持 webDriver API。
selenium 是一个大而全的解决方案,可以用 C#, Java, JS, Python,Ruby 开发,支持 IE,FireFox, Safari,Chrome,andriod Chrome。 selenium 的目的是一套脚本运行在不同浏览器上,可以做兼容性测试。

puppeteer 专注于 Chromium 的功能测试,目前只能使用 js 开发, 如果不考虑兼容性,puppeteer 可以带来更好的性能(少了一层调用的原因),更多的功能。